In this article I address the pros and cons of using an entity-attribute-value (EAV) data model over a static/strongly-typed relational data model. If you know what both models are you may think this is a bit of an odd comparison because I’m seemingly comparing a static schema to a specific approach of doing dynamic schema.
The reason I decide to highlight this particular choice is because I find it to be a commonly made one. The majority of the systems I encounter already use a relational database. When you’re doing data modeling for your enterprise business application the jump between a classic static schema (column per attribute) and an EAV schema in the same relational database can be subtle and thus easily made too quickly. It’s easy to consider EAV as a ‘small difference in doing things’.
I won’t be elaborating a lot on the general decision between static vs dynamic schema’s because the jump from a static schema to other forms of dynamic schema, like storing JSON or XML in the database is already non-subtle and should ring bells to developers that this may be an impactful decision. That decision is also mostly dependent on user requirements whereas EAV could be a purely technical implementation decision.
My goal with this article is to warn anyone thinking about using an EAV data model to approach such a decision with extreme caution and consider alternatives before it.
What is EAV?
For those unfamiliar, an EAV is a data model where you model each attribute of an entity as a separate row in a table with typically at least three columns: entityID, attributeID, value. This is in contrast with a conventional static schema where you create a column per entity-attribute and the entire entity is a single row with (possibly NULL) values for each column. The EAV pattern is often used in CRM systems like WordPress, Magento and medical software. It’s main advantage is flexibility. Read this for more information on EAV. It’s generally considered an antipattern.
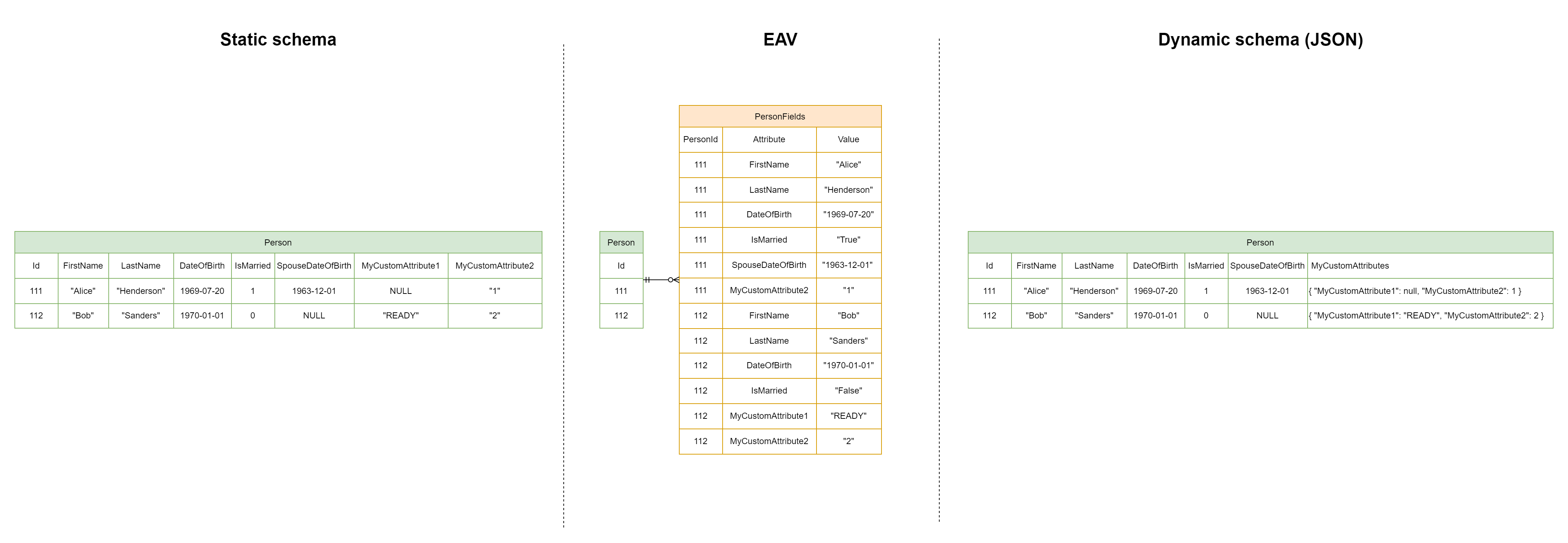
Compared to a static data model, EAV data model has the following cons:
To get to the point, I’ll start with the cons of an EAV. Some of the cons below are true for dynamic schemas in general, but most apply to EAV in particular. I already explained why I mix both in this list.
- Slower query performance.
- Significant complexity required to achieve database type validation. Simple EAV-implementations skip this altogether in favor of using strings for all values and casting to the right value on-demand.
- Loss of referential integrity checks on attribute values. Mitigating this by adding extra columns introduces the risk of bloating the table with unused null columns on many of the value records (something static schema’s have as well)
- Database size can generally end up bigger. Even when EAV is compared to other dynamic schema’s (EAV can be 3x bigger than PostgreSQL’s dynamic jsonb schema ). An exception would be if you have a lot of NULL values in your static schema.
- Validating that only allowed attributes can be inserted as records becomes more complex as that requires a JOIN on the attributes definition list.
- Validating that the same attribute doesn’t appear twice for an entity requires application-level checks.
- Checking if all required attributes are present for a given entity is logic that databases typically do very well. That’ll be well-tested and very robust. With EAV this check is now pushed to the application(s) which introduces risk of bugs and reduces confidence in the database’s data integrity.
- Integrating your data with third party systems could become harder as many systems don’t use EAV models which means you’ll have to map your EAV to a stable model. This mapping could be transient or permanent (e.g. materialized views).
- Slower application performance when accessing individual attributes if all attributes are loaded upfront because of in-memory collection traversal to find the right attribute.
- Worse developer experience (DX) because as a developer reading the code you don’t know which attributes are possible and what types they have
- Worse DX because accessing individual attributes that are in a collection is less convenient than direct property access.
- If pairing the EAV with the runtime ability to create new attributes, this can introduce a magnitude of extra complexity if these individual attributes are ever used in logic (checks) later. Every such attribute is another permutation of the system that you and your team will have to understand and maintain. Don’t underestimate this cost.
Note 9, 10 and 11 could be mitigated with a more permanent mapping to a static model (e.g. a materialized view) but if you’re able to do that, chances are you could’ve just used a static model to begin with.
In general you end up reinventing many constraints that a relational database already has built-in. EAV is therefore an example of the Inner-Platform effect.
Pros of EAV compared to having a static schema:
- Allows runtime definition of attributes. A powerful but dangerously complex feature that in my opinion needs to be used as little as possible.
Creating/updating/deleting tables on the fly or a JSON schema are alternate paths that can also achieve this but with less cons. I have a note on this later in the article. - DB size can be smaller if the dataset with a static schema would have many NULL columns (sparse dataset).
- Allows for rapid prototyping because it’s easier to iterate on data models without requiring database migrations
Pros of EAV compared to a JSON schema in a (hybrid) SQL database.
- Performance, sometimes. On a few very specific queries, like update-an-individual-attribute it could outperform JSON by a bit.
Note that some comparisons compare JSON using PostgreSQL (with its GIN indexes optimizing JSON queries) and EAV. In these examples PostgreSQL can beat EAV in multiple scenarios.
However when comparing SQL Server (which stores JSON as a NVARCHAR “text” field) to EAV, performance comparisons would be different, as SQL Server does not have the same level of JSON optimization as PostgreSQL. So if you’re using SQL server (e.g. because of customers demanding it because they use the Microsoft ecosystem on-premises) and you expect to frequently filter on random dynamic attributes and need this to be a fast query even with 100k+ entities, then consider EAV. EAV allows for indexing on the value column which avoids full table scans.
Note if you are frequently filtering on just a common few dynamic attributes then with the SQL Server JSON approach you can create a few computed columns and create indices on that to optimize performance (use HasComputedColumnSql in EF). Note persisted columns are fastest.
Of course, using computed columns implies knowledge of the dynamic fields’ names which raises the question why not add these (nullable) columns to the static schema? But this could be a nice middle road if it’s not feasible to extract this dynamic field into the static schema due to code-level concerns. - Legacy database support. Back in the older days, pre 2014/json-hybrid sql databases, it could be significantly faster updating or selecting individual attributes due to the overhead of manual (application-level) JSON parsing of the varchar column. Now that we’ve had SQL databases with ‘native’ support for JSON for a long time these arguments do not really apply anymore, except my previous point. If you do for some odd reason still have to support old SQL databases then this could still be a valid reason to consider EAV.
A note on (runtime) flexibility
This snippet from an answer by Homan on StackOverflow summarizes my experience with favoring flexibility over simplicity. It describes the potential pain a dynamic schema can bring.
“Looking back, JSON allowed us to iterate very quickly and get something out the door. It was great. However after we reached a certain team size it’s flexibility also allowed us to hang ourselves with a long rope of technical debt which then slowed down subsequent feature evolution progress. Use with caution.
Think long and hard about what the nature of your data is. It’s the foundation of your app. How will the data be used over time. And how is it likely TO CHANGE?
A particular large source of complexity is a runtime flexible datamodel, where the attributes can be modified by users while the application is running. A great post on the price of runtime flexibility is written by Heaton Cai here.
My advice
My advice when making the decision: always go for a static schema first. Do enough design work to keep it static. That is, let your static schema evolve and grow naturally.
Note this may slowdown initial development because you’ll have to think more and talk to stakeholders more. For this I recommend strategic DDD (specifically ubiquitous language) to reduce the risk of large rework of strongly typed models. In practice this means sit-downs with the business stakeholders and forcing them to decide which attributes they want to capture ahead of time and syncing the models and attributes in code with the models in the head of the stakeholders.
Only if you’ve done that and still come to the conclusion that a small set of attributes really warrant a dynamic schema, implement this using a hybrid NoSQL/JSON approach. That approach brings with it far less complexity compared to an EAV and thus warrants the win already. Not even taking into account that JSON generally outperforms EAV if you’re using PostgreSQL.
Avoid the trap of making many attributes dynamic. If you find yourself doing that, consider a document or key-value database instead.
Note this is my personal heuristic that I apply in many contexts. Realize all contexts are different and decisions should be based on tradeoffs within those contexts.
I like this quote highlighting this on the topic of EAV:
“I’m sure there are more things you could list in the pros and cons for each option. The point is you make this list, then assess which option has the most upside for the least downside for you. For example, most of the downsides for the “full relational” tables relate to speed of delivery. If new attributes pop up daily, this is a problem. But if something new comes along only once a year, this is practically a non-issue.”
Chris on asktom.oracle.com
Kind regards,
Sanchez
Leave a Reply